Recreational Programming with Serverless
This article is a slightly edited version of the presentation I gave at the AWS Community Day 2019 in Hamburg, Germany. You can find the original slides here. There’s no recording available, so you have to take my word that the following actually happened.
I know it’s been nine months since the event took place, but I still find myself thinking about the importance of recreational programming, especially in difficult times like this. That’s why I decided to share the full content here and now. Besides, following the “show, don’t tell” rule, I’ve recently open sourced the serverless project that is at the heart of the talk.
One more note before we get started: If I appear overly critical of Kubernetes at times, it’s because I tell the story from the perspective of someone who’s built and operated container systems in different cloud environments since 2015. Mere users of Kubernetes will undoubtedly appreciate it more than I do. Complexity has to live somewhere, after all.
In any case, enjoy the presentation.

Hello, and welcome to my lightning talk on recreational programming with serverless!

I want to start with a little introduction. My name is Mathias Lafeldt. I’m from a small town north of Hamburg, so I’m a local if you will.
I’ve been using AWS since 2013. These days, I help companies embrace the cloud as a freelancer – a very happy freelancer, to be honest.

Most of my current consulting work focuses on Kubernetes and AWS. I help teams set up AWS accounts in a sustainable way, do network planning, pick the right cluster setup for them, create CI/CD pipelines, implement monitoring, etc. – basically, all those things that are required to make any use of Kubernetes on AWS.
As a freelancer, I see a high demand for migrating software to the cloud. A lot of organizations choose Kubernetes for modernizing their legacy applications. I understand the reasoning behind this decision:
- It’s relatively easy to package your code and move it (almost as-is) to the cloud in the form of containers.
- Kubernetes streamlines the development process by automating the deployment and scaling of containerized applications.
I think it’s true that Kubernetes can provide value. However…

It’s also true that Kubernetes is a complex beast with many moving parts, and therefore many different failure modes. To make matters worse, it’s growing by the minute as its ecosystem is constantly evolving.
You may know this website. It was created by Henning Jacobs from Zalando. He built this collection of Kubernetes failure stories for people to learn from each other and not repeat the same mistakes again and again.
For me, this site’s sheer existence is a testament to the fact that there’s a lot to deal with when you want to be successful with Kubernetes in production.
I like to joke that (self-hosted) Kubernetes clusters are the perfect job creation measure. They’re also well suited if you want to get good at writing postmortems. I know it first-hand, as I had to write a couple of those myself…
Now you may ask, what about EKS, Amazon’s managed Kubernetes service? [The talk right before mine was about EKS.]
From my experience, EKS offers significant advantages over tools like kops. For one, it will give you a managed control plane that takes care of running the API servers and etcd for you. However, you still need to bring your own EC2 worker nodes, which means you’re still responsible – at least to a degree – for high availability, AMI updates, EBS volumes, backups, VPC design, load balancers, and much more.
[Note: AWS has released EKS managed node groups in the meantime, which certainly reduces the total cost of ownership (TCO) of Kubernetes clusters, especially when it comes to updating worker nodes. The overall TCO nevertheless continues to represent a significant administrative burden on the shoulders of operators. Configuration of Kubernetes remains a non-trivial task.]

While Kubernetes might be perfect for you or your company (understandably so given its advantages), I personally find working with it for extended periods exhausting. As a cluster operator, it’s stressful to be on the hook for so many things that can go wrong – and will go wrong, as demonstrated by the failure stories website mentioned earlier.
Ultimately, it should be about the applications, right? We don’t have a Kubernetes cluster just for the sake of having a Kubernetes cluster. Its whole purpose is to make it easy for us to deploy, scale, and manage our containerized applications.
Sadly, despite considerable efforts, we still get sucked into a never-ending cycle of operational tasks, tasks we never signed up for. The result for me has been mental fatigue and, at times, lack of motivation to deal with such systems.

At some point, I discovered a podcast episode with Jamis Buck. Jamis is a famous programmer. He created Capistrano and plenty more open source projects. On the show, he talks about how he used to be on the top of the world about ten years ago. He worked for 37signals (now called Basecamp), earned a big paycheck, everything seemed perfect. There was only one problem: he was burnt out.
As a consequence, he had to let go of most of his side projects. Unfortunately, that didn’t help much. To overcome burnout, he left his fantastic job and decided to write a book on one of his passions: generating mazes. Mazes helped Jamis remember what got him excited about programming initially. Mazes are his form of recreational programming.
I was wondering what my kind of recreational programming would be? Maybe I already found it but didn’t know it yet.
Werner Vogels recently published a blog post titled “Modern applications at AWS”. In it, he describes how Amazon has been successful for 20 years by going through a series of radical transformations, always questioning how they build applications and how they organize the company.

According to Werner, organizations must adopt five elements to increase agility and innovation speed:
- Embrace microservices to decouple systems and enable autonomous, cross-functional teams.
- Use purpose-built databases for each microservice rather than a single database for all microservices, which can’t meet specific needs and is a single point of failure.
- Enable teams to release changes independently, for example, by providing best-practice infrastructure-as-code templates.
- The same goes for security as “in modern applications, security features are built into every component of the application and automatically tested and deployed with each release.”
- Be as serverless as possible and offload undifferentiated tasks to AWS services such as Lambda.

Even Amazon is not completely serverless yet, but they’re getting there. Werner believes that thanks to serverless, there will soon be a whole generation of developers who have never touched a server and only write business logic.
That sounds like a bright future to me. ☀️

Of course, there’s more to serverless than programming with Lambda. For starters, it’s not just Lambda but the entire application stack, including services like DynamoDB, S3, SNS, API Gateway, etc. More generally speaking:
- Serverless services are managed services that run without the need for infrastructure provisioning and scaling.
- They provide built-in availability and security. No need to care about availability zones or kernel patches.
- You only pay for what you use. You don’t pay for idle resources.
- Serverless allows you to focus on business logic – your “secret sauce”, the things that set you apart from your competition.
- With serverless, you can create value for customers faster.
Looking at this list made me pause for a second. Those are indeed excellent reasons for startups and enterprises to go serverless.

More to the point, I realized that a lot of properties that make serverless great for businesses – no servers to manage, easy deployments, pay-as-you-go with a generous free tier – also make it a great fit for recreational programming!
One advantage stands out in particular to me: the ability to concentrate on my applications – the serious ones and the not-so-serious ones.

Next, I want to show you a few serverless projects I created for fun, projects I consider recreational in some sense.
I’m a huge fan of Dilbert and a couple of other comic strips. I also love reading articles and comics using my favorite RSS feed reader: Feedly on iOS.
The problem with Dilbert is that although there’s an official RSS feed, it no longer includes the comic strips themselves but only links to dilbert.com. How mean and inconvenient!
In 2017, I started looking at this obstacle as an opportunity for an interesting serverless application – bluntly named dilbert-feed – to create my own feed that I can enjoy in Feedly again.
Here’s how I went about it.
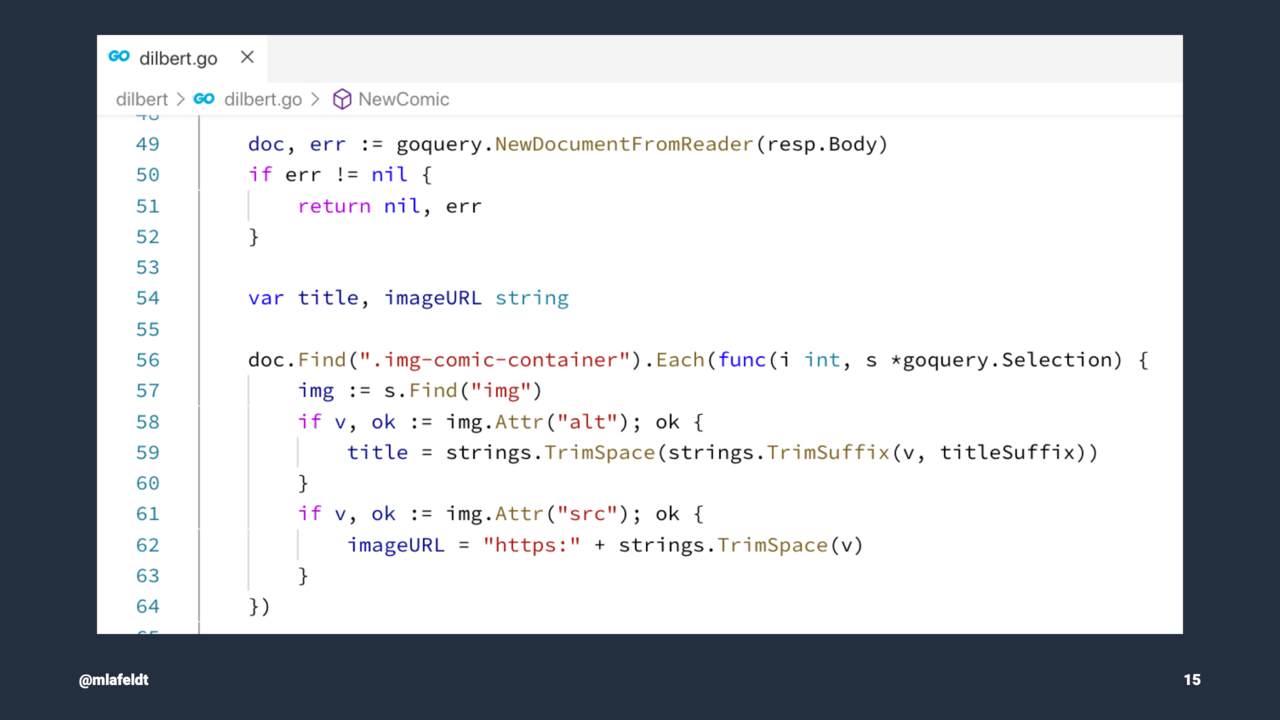
First of all, I had to figure out how to get the images. Fortunately, Dilbert is a daily strip and the URLs are predictable, e.g., dilbert.com/strip/2019-08-30. That means I only had to download the web page for a given day and parse the HTML to get a link to the image.
I decided to use Go – my favorite programming language – for the job. I was lucky to find the superb goquery package, which does most of the work for me, as you can see on the slide above.
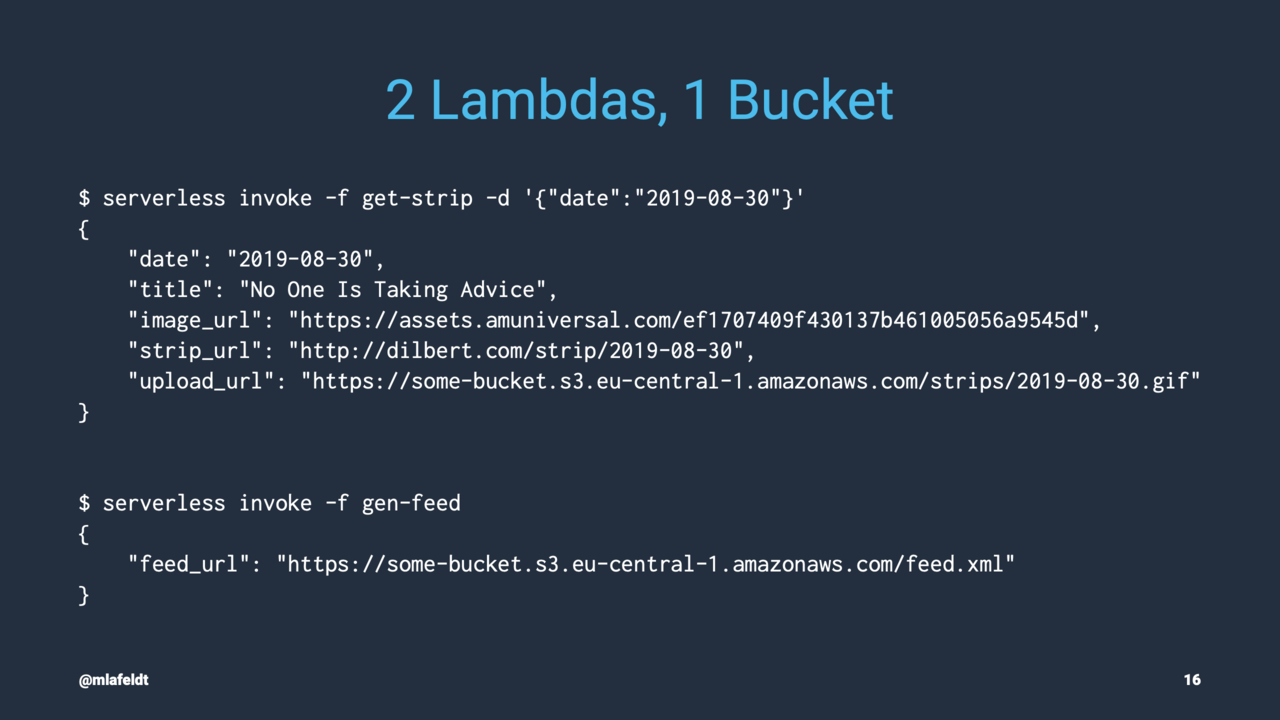
Now that I knew how to get the images, I used the Serverless Framework to turn that code, which has to be deployed somewhere where it can be invoked once a day, into a Lambda function called get-strip. After determining the image URL, the function will copy the found image to an S3 bucket via the always handy AWS SDK for Go.
To separate concerns, I wrote another Lambda named gen-feed that generates the RSS feed for the last 30 days (for this, all it needs to know is the location of the images uploaded by get-strip).
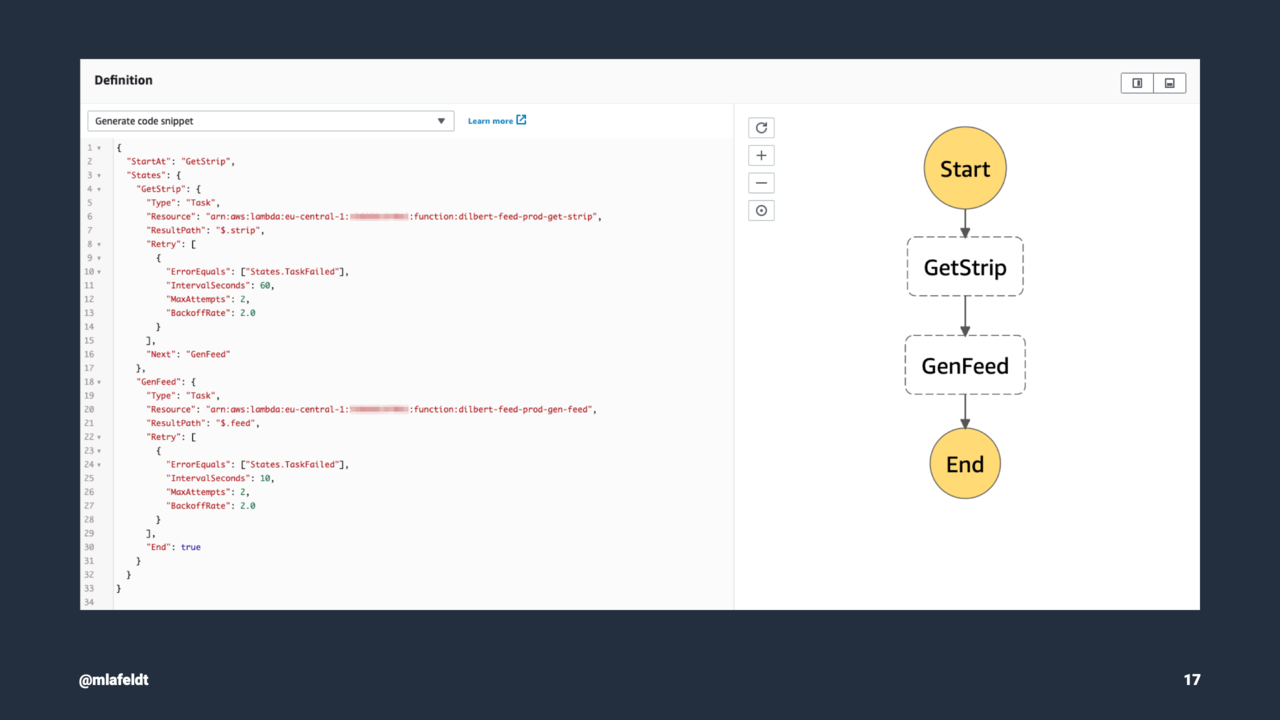
For the feed to be consistent (and to make the task a bit more challenging), the two functions should run in sequence. But instead of staggering the Lambdas via two cron jobs, I chose to give AWS Step Functions a spin.
What you see on this slide must be one of the simplest state machines imaginable. While Step Functions is much more powerful, bare-bones orchestration was all I needed to get started.
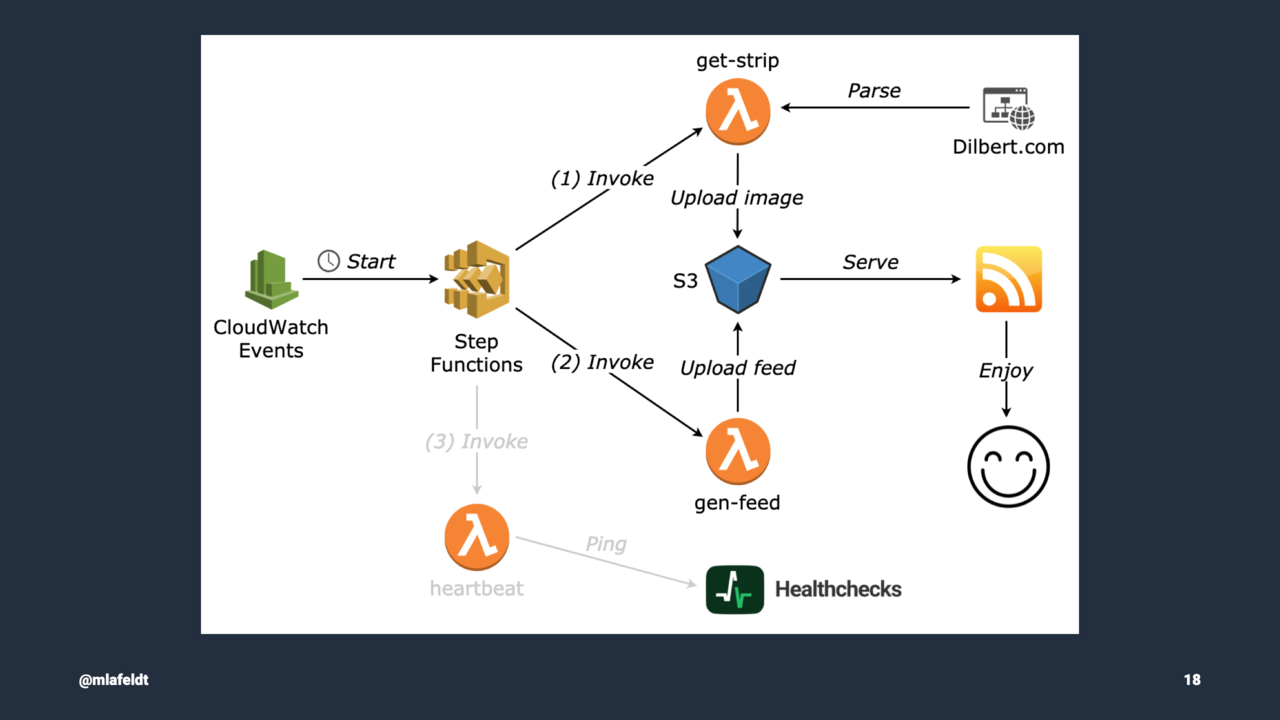
To complete the picture, I created a CloudWatch Events rule for triggering the state machine to update the feed with the latest Dilbert strip every morning. The architecture diagram shows all involved components running inside my personal AWS account (for which I haven’t had to pay a cent so far, by the way).
You’re probably right to assume that dilbert-feed is over-engineered to some degree, and deliberately so. Remember that it’s just a fun side project, a playground where I can do whatever I want and try out new tools and practices whenever I feel like it.
Among other things, I used the project to explore different monitoring/observability solutions for serverless. In the end, I settled for a simple heartbeat Lambda that pings Healthchecks.io over HTTP as the last state machine step.
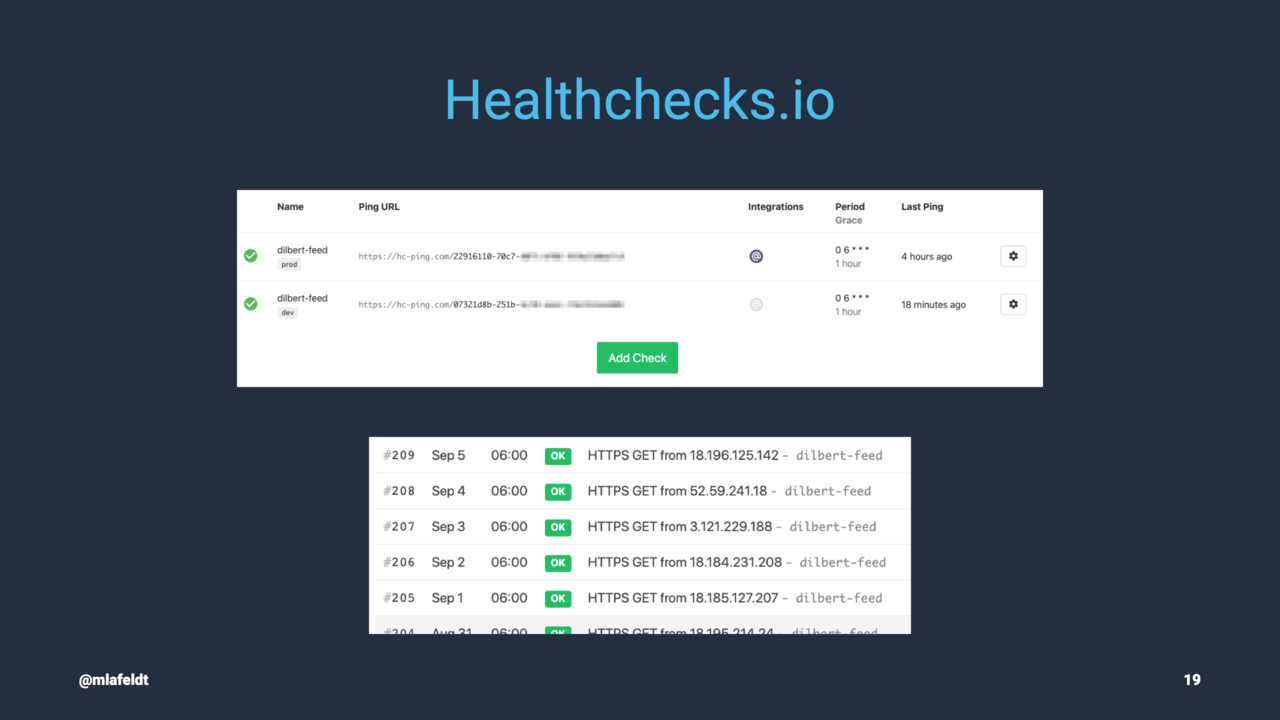
On Healthschecks.io, I’ve configured a check that sends me an email notification as soon as a ping doesn’t arrive on time. It can’t get much easier than that.
In true deploy-once-and-leave-the-rest-to-serverless manner, the setup has been humming along nicely for over two years without significant problems other than dilbert.com being down for maintenance. 💪

As you can see from this list, I learned a great deal from hacking on dilbert-feed on nights and weekends. In fact, it continues to benefit me as a playground and template for other side and freelance projects to this day.
[Shortly after giving the presentation in 2019, I started to embrace the wonderful AWS CDK. Again, all these experiments are open source.]

Before we wrap up, I want to briefly mention two more serverless projects I made for fun.
The first is a DynamoDB Store for LaunchDarkly, which provides the building blocks that, taken together, allow you to create a serverless flag storage pipeline. For more information, check out my presentation on Implementing Feature Flags in Serverless Environments.
Needless to say, this was a good opportunity for diving into DynamoDB.
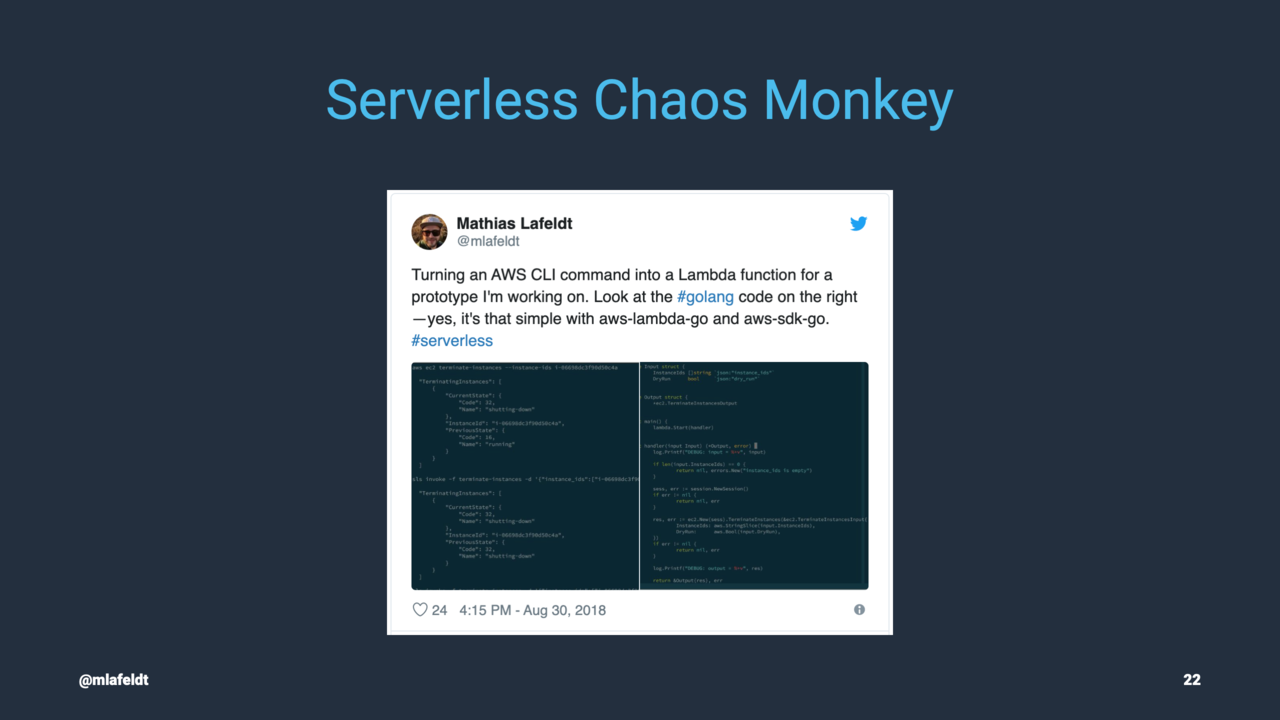
Last but not least, I’ve been tinkering with a serverless version of Chaos Monkey. It’s still work-in-progress, but I hope to share more about it in the future. Suffice to say, Chaos Engineering is near and dear to my heart.
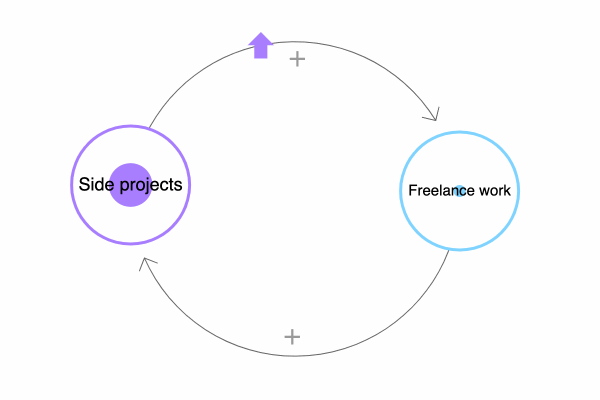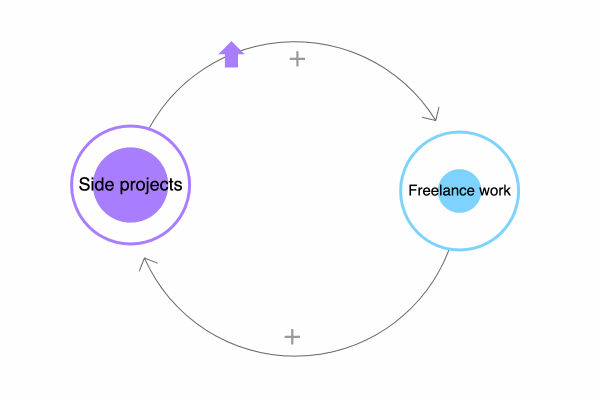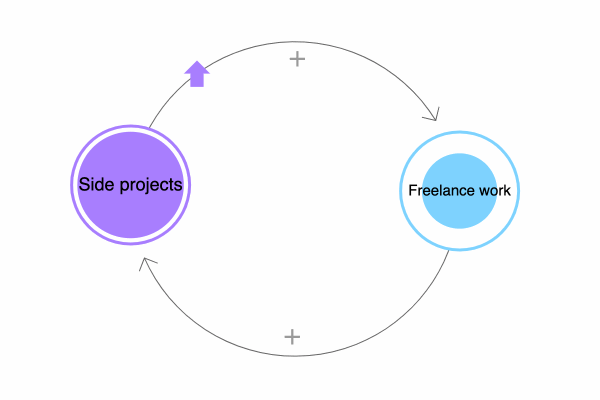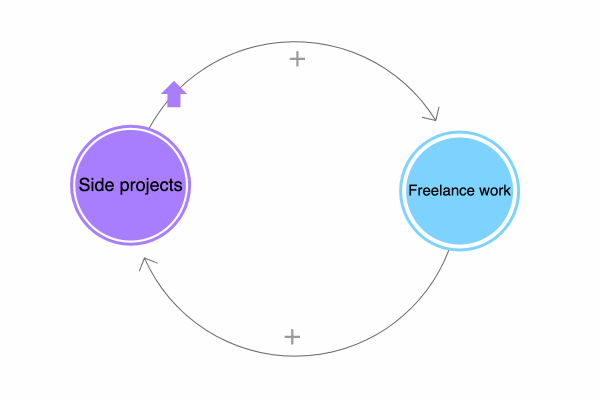
What do all these ventures have in common? They’re part of a positive feedback loop.
Investing time in side projects – or recreational programming in general, the “project” bit is optional – will improve my freelance work, either directly (craftsmanship) or indirectly (motivation). Conversely, the things I learn from consulting can have a regenerative effect on my side projects. It’s a virtuous cycle.
(That said, it’s totally okay and often advantageous if your hobbies have nothing to do with your work. I can only speak for myself.)

Let’s wrap things up. Here are the key takeaways for you:
Cloud projects don’t have to be big or great. Sometimes, it’s enough for them to be fun. For me, serverless is the very definition of fun.
Building things is fulfilling; servers are a distraction from what really matters: our beloved applications.
Serverless has helped me, a consultant who wrestles with Kubernetes by day, rediscover the joy of programming by night.
Serverless is an excellent choice for many endeavors, one of them being recreational programming.

Thank you. 🙏