Embracing Failure in a Container World
What follows is the text of my presentation, Embracing Failure in a Container World that I gave at ContainerDays in Hamburg this year. There’s no recording available, so I figured it would be fun to turn the presentation into an article. I edited the text slightly for readability and added some links for more context. You can find the original slides here.

Hi, and welcome to my talk, “Embracing Failure in a Container World”.
Today I want to show you some practices and tools you can use to make your container systems more resilient to failures.

My name is Mathias.
I’m @mlafeldt on Twitter, GitHub, and pretty much anywhere else on the internet.

I live here in Hamburg and I work remotely for a US startup called Gremlin Inc.
We obviously like to break things on purpose, but I will tell you more about Gremlin at the end of the talk.
Right now, let’s talk about a fun topic…

Outages.
Here are three of the better-known ones from this year:
- GitLab’s infamous “team-member-1” accidentally removed a folder on the wrong server, resulting in a long database outage.
- We probably all noticed the major S3 incident earlier this year, which also affected other AWS services like EC2.
- Last but not least, a recent server outage halted sales at many Starbucks stores in the US, but at least they gave out free coffee.
I bet you also suffered from other outages not listed here.
But what’s the lesson?

The lesson is that sooner or later, all complex systems will fail.
There will always be something that can – and will – go wrong. No matter how hard we try, we can’t build perfect software, nor can the companies we depend on.
Even S3, which has had a long track record of availability, will fail in surprising ways.

I found this quote from Henning’s talk to fit in nicely here. That’s why I turned it into a slide.
Speaking of complex systems that fail, “There’s always something with Docker in production.”
It’s funny because it’s true.

So we live in this imperfect world – things break all the time, that’s just how it is. All we can do is accept it and focus on the things we can control: creating a quality product or service that is resilient to failures.
Add redundancies, use auto scaling, gracefully degrade whenever possible, decrease coupling between system components – those are well-known design patterns to make systems more resilient to failures.

Well, at least that’s the theory. Building robust systems in practice is a lot harder, of course. How do you actually know you’re prepared for the worst in production?
Sure, you can learn from outages after the fact. That’s what postmortems are for. Postmortems are awesome, I’m a big fan. However, learning it the hard way shouldn’t be the only way to acquire operational knowledge.
Waiting for things to break in production is not an option.
But what’s the alternative?

The alternative is to break things on purpose. And Chaos Engineering is one particular approach to doing just that. The idea of Chaos Engineering is to be proactive – to inject failures before they happen in production.
Intentionally terminate cluster machines, delete database tables, inject network latency. Be creative. These actions help us verify that our infrastructure can cope with these failures, and to fix it otherwise.
However, Chaos Engineering is not only about testing assumptions, but it’s also about learning new things about our systems, like discovering hidden dependencies between components.
Chaos Engineering was originally formalized by Netflix. Check out their website – principlesofchaos.org – for more details.

Before we move on, let me give you a bit more context.
It’s fair to say that I learned most of the things I know about web infrastructure in my four years at Jimdo, especially when I was part of the team responsible for Wonderland, which is Jimdo’s internal PaaS.
In fact, we gave a presentation about Wonderland at ContainerDays last year. I want to spare you the details today. It’s enough to say that Wonderland uses ECS under the hood, which is Amazon’s cluster scheduler for Docker containers.
Also, Wonderland powers 100% of Jimdo’s production infrastructure. It’s not just some toy Docker project; it’s the real thing.

Now back to Chaos Engineering.
One thing we did to implement Chaos Engineering at Jimdo was to run so-called GameDay exercises on a regular basis.
On a typical GameDay, we would…
- Gather the whole team in front of a big screen.
- Think up failure modes and estimate the impact of those failures. For example, we asked ourselves, “What would happen if we terminated 5 cluster instances at once or if this critical microservice went down?”
- Go through all chaos experiments together, breaking things on purpose just as we planned.
- Write down the measured impact.
- Create follow-up tickets for all flaws uncovered this way.
I can assure you that we found a number of issues every single time, many caused by missing timeouts and unexpected dependencies, and also some bugs in open source software we were using.
To put it in a nutshell, GameDays are great. They helped us improve Wonderland to the point where we had to test PagerDuty during GameDays to find out if our monitoring was still working – because alerts were so rare.

One particular tool we used during GameDays was Chaos Monkey.
Who of you has used Chaos Monkey before? And in production? (Asking the audience. For the record, only Jimdo employees raised their hands twice.)
Chaos Monkey was built by Netflix to terminate EC2 instances randomly during business hours. The goal is for the infrastructure to survive terminations without any customer impact.
I think you all agree that it’s better to test this proactively in the office than at 4 am in the night when shit really hits the fan.

Unfortunately, the configuration of Chaos Monkey is a bit complex. It’s a Java program that has dozens and dozens of settings. That was one problem, the other one was deployment.
Since we already had this amazing container platform at Jimdo, I decided to dockerize Chaos Monkey and solve the configuration issue at the same time.
This Docker image is the result. We ended up using it to run one monkey per environment (one in staging, one in production), which gave us a solid foundation for running chaos experiments on GameDays.

To give you an example, this shows the basic usage of the Docker image.
We pass the required AWS credentials to the image and instruct it to consider all EC2 auto scaling groups of the corresponding AWS account for termination.
When running, Chaos Monkey will randomly pick one auto scaling group and terminate one instance of that group. That’s how it works.

Chaos Monkey usually runs continuously, killing an instance every hour or so. However, we only needed it during GameDays or whenever we had to do some resilience testing.
Luckily, Chaos Monkey also comes with a REST API that allows us to terminate instances on demand. And I wrote a command-line tool in Go to make use of that API.

Again, here’s an example.
We first install the chaosmonkey command-line tool using go get.
We then tell it where Chaos Monkey is running, what auto scaling group we want to target, and how the instance should be terminated (Chaos Monkey supports different chaos strategies, with “shutdown” being the default).
We can also be fancy and terminate multiple instances in a row, which is helpful to find out when a cluster loses quorum, for example.
The tool can do a couple more things not shown here. I recommend checking out the README on GitHub for more information.
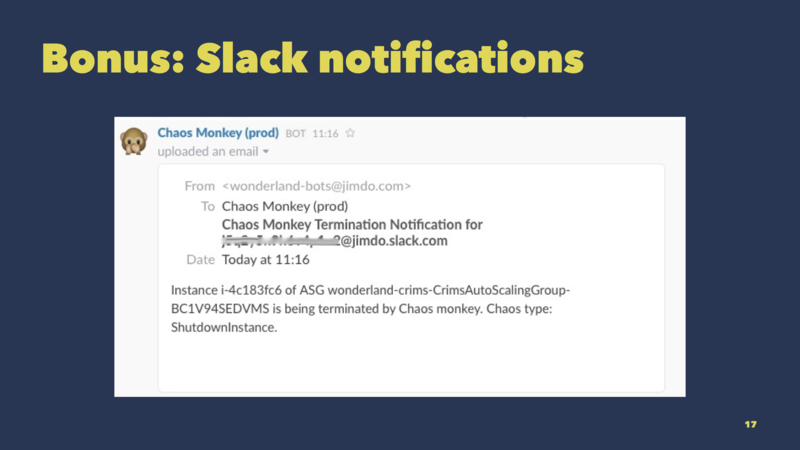
One last tip on Chaos Monkey:
It’s possible to hook it up to Slack so that your team is aware of ongoing chaos experiments. This slide shows an example message from one of our Slack channels.
For obvious reasons, visibility is important when doing Chaos Engineering.

So far, we talked about Chaos Monkey and how it can be used to terminate instances. Of course, terminating hosts is only one way to inject failures into your system. There’s certainly a lot you can learn from this exercise, but there are also many more places where your infrastructure can fail.
We are at ContainerDays, so I guess we’re interested in impacting not only the hosts where our containers are running on but also the containers themselves, right?

This is where Pumba comes in.
Pumba is an open source tool designed for injecting failures into running Docker containers. Just as Chaos Monkey, you can use it to simulate real-world events. For example, you can kill specific containers or inject network errors into them.
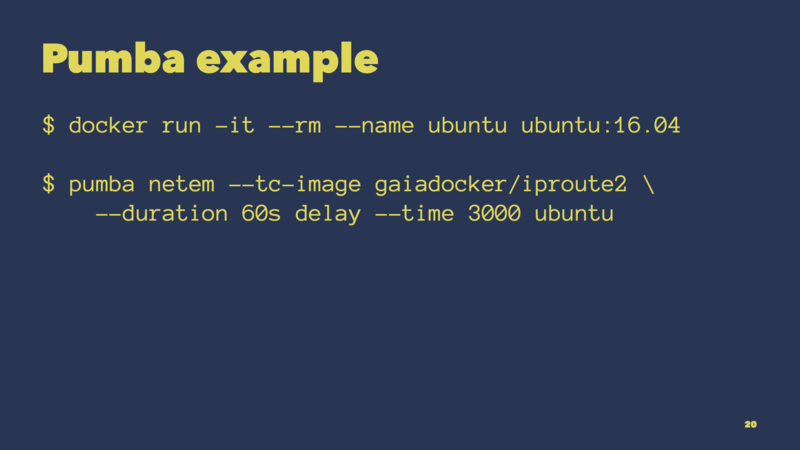
Here’s an example showing Pumba in action.
We first start a test Ubuntu container. We then instruct Pumba to delay all outgoing network traffic from that container for 60 seconds. That’s basically how you can simulate latency to external services used by an application running in that container.

Now you might wonder how this works under the hood.
Internally, Pumba uses a tool called tc that talks to the traffic shaping API of the Linux kernel. However, it would be impractical to bake tc into every application container you want to attack.
So what Pumba does is spawn a sidecar container, which has tc preinstalled. And it will spawn that sidecar container in the network namespace of the target Ubuntu container. That’s what the --net option does here.
When done, Pumba will do the same thing to remove the traffic rule from the kernel again.
Pretty magical, but works well in practice.

At the beginning of the talk, I promised you to tell you more about Gremlin Inc.
So what do we do?

Gremlin, our product, provides failure as a service. It’s another powerful tool for resilience testing.
You can use Gremlin to attack hosts and containers. In the future, it will also be possible to attack applications directly through application-level fault injection.
We support a variety of attacks that you can run from our Web UI or the command line. One unique feature of Gremlin is that it can safely revert all impact. We also provide security features like auditing and access control out of the box.
Gremlin is currently in closed beta. If you want to give it a try, talk to me, and I will send you an invite.

Let’s wrap this up. What are the takeaways from this talk?
The main takeaway is that building resilient systems requires experience with failure. Don’t wait for things to break in production, but rather inject failure proactively in a controlled way.
Use one or more of the many chaos tools available today. Use Chaos Monkey, use Pumba, use Gremlin – whatever works for you.
Please keep in mind that it’s important to start small! Don’t wreak havoc on production from day one and tell your boss it was my idea. Instead, start by experimenting with a virtual machine or a staging environment. Then slowly ramp up your testing efforts.

For those of you who have enjoyed this presentation and want to learn more about Chaos Engineering or SRE in general, I wrote a lot of articles on these topics in the last year. Check out my Production Ready mailing list and feel free to talk to me about anything afterward.

Thank you.